
 duyong mac
c3cc723770
logs包
duyong mac
c3cc723770
logs包
|
hace 5 meses | |
|---|---|---|
| .. | ||
| img.png | hace 5 meses | |
| img_1.png | hace 5 meses | |
| img_2.png | hace 5 meses | |
| img_3.png | hace 5 meses | |
| img_4.png | hace 5 meses | |
| readme.md | hace 5 meses | |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
readme.md
日志包设计理念
1. 如何设计日志包
1.1. 基础功能
1.1.1 支持基本的日志信息
日志包需要支持基本的日志信息,包括时间戳、文件名、行号、日志级别和日志信息
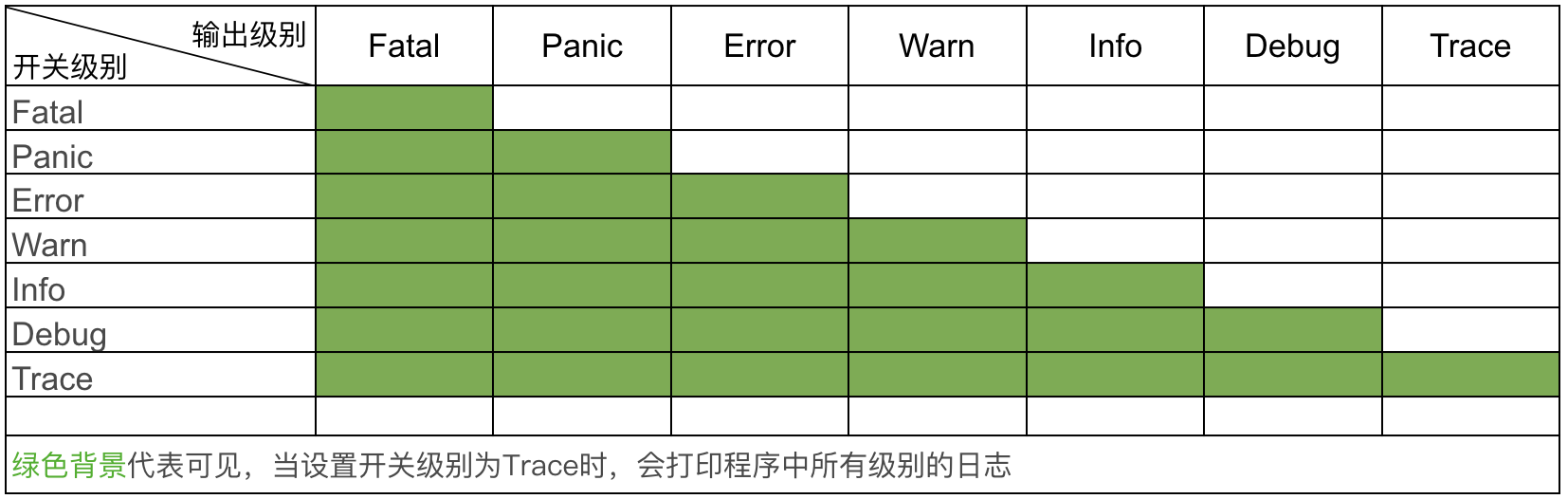
1.1.2 支持不同的日志级别
通常一个日志包至少要实现 6 个级

1.1.3 支持自定义配置
不同的运行环境,需要不同的日志输出配置 例如:开发测试环境为了能够方便地 Debug,需要设置日志级别为 Debug 级别; 现网环境为了提高应用程序的性能,则需要设置日志级别为 Info 级别。 又比如,现网环境为了方便日志采集,通常会输出 JSON 格式的日志; 开发测试环境为了方便查看日志,会输出 TEXT 格式的日志。
1.1.4 支持输出到标准输出和文件
日志总是要被读的,要么输出到标准输出,供开发者实时读取,要么保存到文件,供开发者日后查看。输出到标准输出和保存到文件是一个日志包最基本的功能。
1.2 高级功能
1.2.1 支持多种日志格式
一个日志包至少需要提供以下两种格式:
- TEXT 格式:TEXT 格式的日志具有良好的可读性,可以方便我们在开发联调阶段查看日志
- JSON 格式:JSON 格式的日志可以记录更详细的信息,日志中包含一些通用的或自定义的字段,可供日后的查询、分析使用,而且可以很方便地供 filebeat、logstash 这类日志采集工具采集并上报
1.2.2 能够按级别分类输出
为了能够快速定位到需要的日志,一个比较好的做法是将日志按级别分类输出,至少错误级别的日志可以输出到独立的文件中。这样,出现问题时,可以直接查找错误文件定位问题.
1.2.3 支持结构化日志
结构化日志(Structured Logging),就是使用 JSON 或者其他编码方式使日志结构化,这样可以方便后续使用 Filebeat、Logstash Shipper 等各种工具,对日志进行采集、过滤、分析和查找
1.2.4 支持日志轮转
为了防止日志把磁盘空间占满,导致服务器或者程序异常,就需要确保日志大小达到一定量级时,对日志进行切割、压缩,并转存。
lumberjack 可以支持按大小和日期归档日志
file-rotatelogs支持按小时数进行日志切割
对于日志轮转功能,不建议在日志包中添加,因为这会增加日志包的复杂度,我更建议的做法是借助其他的工具来实现日志轮转。 例如,在 Linux 系统中可以使用 Logrotate 来轮转日志。Logrotate 功能强大,是一个专业的日志轮转工具。
1.2.5 具备 Hook 能力
Hook 能力可以使我们对日志内容进行自定义处理。例如,当某个级别的日志产生时,发送邮件或者调用告警接口进行告警。
1.3 可选功能
1.3.1 支持颜色输出
在开发、测试时开启颜色输出,不同级别的日志会被不同颜色标识,这样我们可以很轻松地发现一些 Error、Warn 级别的日志,方便开发调试。发布到生产环境时,可以关闭颜色输出,以提高性能。
1.3.2 兼容标准库 log 包
1.3.3 支持输出到不同的位置
在分布式系统中,一个服务会被部署在多台机器上,这时候如果我们要查看日志,就需要分别登录不同的机器查看,非常麻烦。我们更希望将日志统一投递到 Elasticsearch 上,在 Elasticsearch 上查看日志。
我们还可能需要从日志中分析某个接口的调用次数、某个用户的请求次数等信息,这就需要我们能够对日志进行处理。一般的做法是将日志投递到 Kafka,数据处理服务消费 Kafka 中保存的日志,从而分析出调用次数等信息。
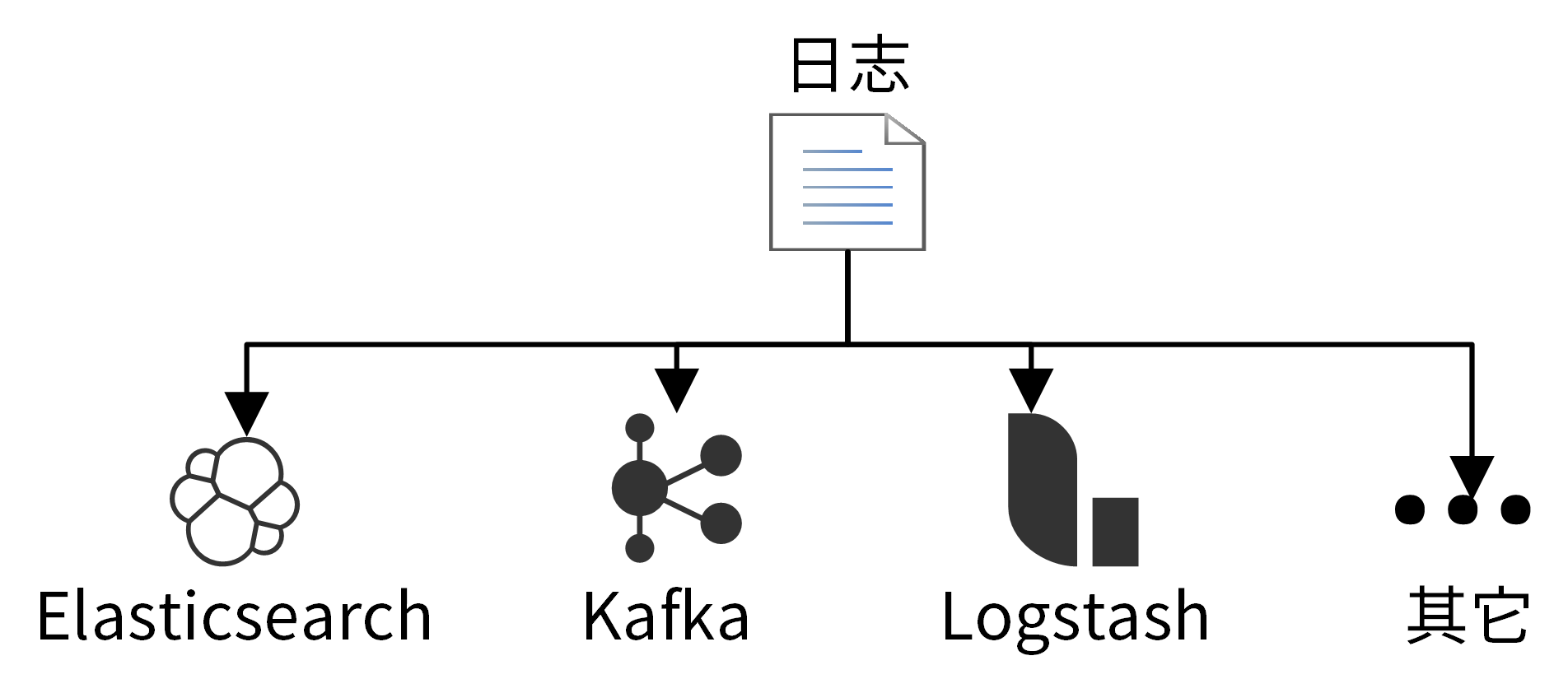
如果日志不支持投递到不同的下游组件,例如 Elasticsearch、Kafka、Fluentd、Logstash 等位置,也可以通过 Filebeat 采集磁盘上的日志文件,进而投递到下游组件。
2. 涉及日志包需要关注的点
- 高性能:因为我们要在代码中频繁调用日志包,记录日志,所以日志包的性能是首先要考虑的点,一个性能很差的日志包必然会导致整个应用性能很差。
- 并发安全:Go 应用程序会大量使用 Go 语言的并发特性,也就意味着需要并发地记录日志,这就需要日志包是并发安全的。
- 插件化能力:日志包应该能提供一些插件化的能力,比如允许开发者自定义输出格式,自定义存储位置,自定义错误发生时的行为(例如 告警、发邮件等)。插件化的能力不是必需的,因为日志自身的特性就能满足绝大部分的使用需求,例如:输出格式支持 JSON 和 TEXT,存储位置支持标准输出和文件,日志监控可以通过一些旁路系统来实现。
- 日志参数控制:日志包应该能够灵活地进行配置,初始化时配置或者程序运行时配置。例如:初始化配置可以通过 Init 函数完成,运行时配置可以通过 SetOptions / SetLevel 等函数来完成。
3. 如何记录日志
日志并不是越多越好,在实际开发中,经常会遇到一大堆无用的日志,却没有我们需要的日志;或者有效的日志被大量无用的日志淹没,查找起来非常困难。
一个优秀的日志包可以协助我们更好地记录、查看和分析日志,但是如何记录日志决定了我们能否获取到有用的信息。日志包是工具,日志记录才是灵魂。这里,我就来详细讲讲如何记录日志。
3.1 在何处打印日志
- 在分支语句处打印日志。在分支语句处打印日志,可以判断出代码走了哪个分支,有助于判断请求的下一跳,继而继续排查问题。
- 写操作必须打印日志。写操作最可能会引起比较严重的业务故障,写操作打印日志,可以在出问题时找到关键信息。
- 在循环中打印日志要慎重。如果循环次数过多,会导致打印大量的日志,严重拖累代码的性能,建议的办法是在循环中记录要点,在循环外面总结打印出来。
- 在错误产生的最原始位置打印日志。对于嵌套的 Error,可在 Error 产生的最初位置打印 Error 日志,上层如果不需要添加必要的信息,可以直接返回下层的 Error
3.2 在哪个日志级别打印日志
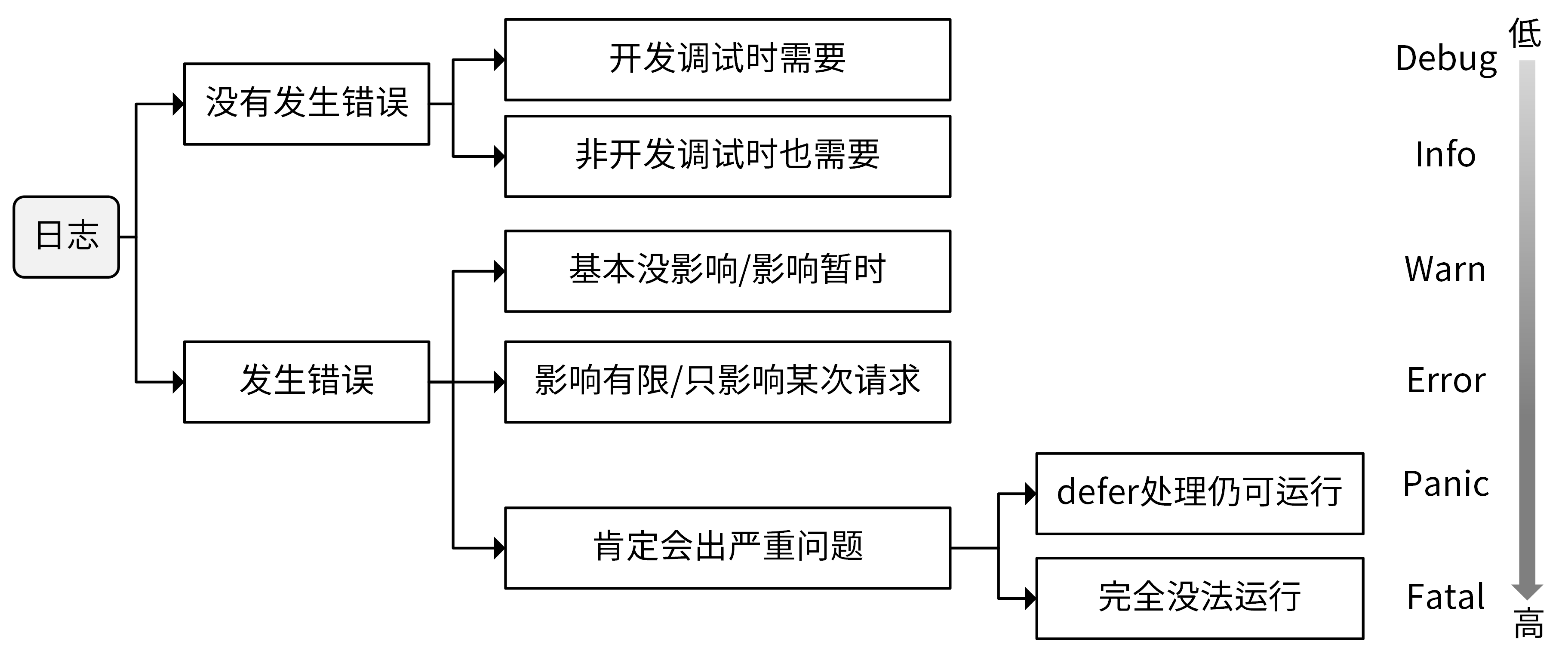
3.3 如何记录日志内容?
- 在记录日志时,不要输出一些敏感信息,例如密码、密钥等。
- 日志内容应该小写字母开头,以英文点号 . 结尾,例如 log.Info("update user function called.")
- 为了提高性能,尽可能使用明确的类型,例如使用 log.Warnf("init datastore: %s", err.Error()) 而非 log.Warnf("init datastore: %v", err) 。
- 根据需要,日志最好包含两个信息。一个是请求 ID(RequestID),是每次请求的唯一 ID,便于从海量日志中过滤出某次请求的日志,可以将请求 ID 放在请求的通用日志字段中。另一个是用户和行为,用于标识谁做了什么。
- 不要将日志记录在错误的日志级别上。
4. 分布式日志解决方案(EFK/ELK)
在实际 Go 项目开发中,为了实现高可用,同一个服务至少需要部署两个实例,通过轮询的负载均衡策略转发请求。 另外,一个应用又可能包含多个服务。假设我们的应用包含两个服务,每个服务部署两个实例,如果应用出故障,我们可能需要登陆 4(2 x 2)台服务器查看本地的日志文件,定位问题,非常麻烦,会增加故障恢复时间。 所以在真实的企业场景中,我们会将这些日志统一收集并展示。
在业界,日志的收集、处理和展示,早已经有了一套十分流行的日志解决方案:EFK(Elasticsearch + Filebeat + Kibana)或者 ELK(Elasticsearch + Logstash + Kibana),EFK 可以理解为 ELK 的演进版,把日志收集组件从 Logstash 替换成了 Filebeat。 用 Filebeat 替换 Logstash,主要原因是 Filebeat 更轻量级,占用的资源更少。关于日志处理架构,你可以参考这张图。

通过 log 包将日志记录在本地文件中(*.log 文件),再通过 Shipper 收集到 Kafka 中。Shipper 可以根据需要灵活选择,常见的 Shipper 有 Logstash Shipper、Flume、Fluentd、Filebeat。其中 Filebeat 和 Logstash Shipper 用得最多。Shipper 没有直接将日志投递到 Logstash indexer,或者 Elasticsearch,是因为 Kafka 能够支持更大的吞吐量,起到削峰填谷的作用。
Kafka 中的日志消息会被 Logstash indexer 消费,处理后投递到 Elasticsearch 中存储起来。Elasticsearch 是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能。Elasticsearch 中存储的日志,可以通过 Kibana 提供的图形界面来展示。 Kibana 是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 中的日志数据。
Logstash 负责采集、转换和过滤日志。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。 Logstash 又分为 Logstash Shipper 和 Logstash indexer。其中,Logstash Shipper 监控并收集日志,并将日志内容发送到 Logstash indexer,然后 Logstash indexer 过滤日志,并将日志提交给 Elasticsearch。
5. 本日志包实现
该 log 包是基于 go.uber.org/zap 包封装而来的